Abstract
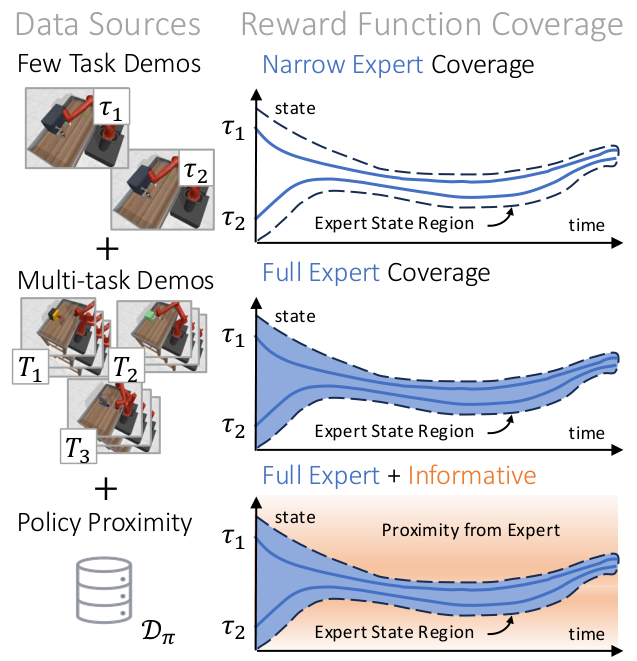
Inverse reinforcement learning (IRL) provides a powerful framework for learning from demonstrations. However, real-world tasks often exhibit substantial natural variations (e.g., picking up mugs with varying shapes), making it impractical to collect demonstrations that fully specify a new task under every possible scenario. In practice, while demonstrations for the target task are limited, it is often easier to obtain datasets of heterogeneous but related behaviors. This motivates the problem of few-shot IRL with multi-task demonstrations (FM-IRL), where an agent must learn a new task with substantial variations from only a limited number of target-task demonstrations, together with sufficient demonstrations of related tasks and online agent experience.
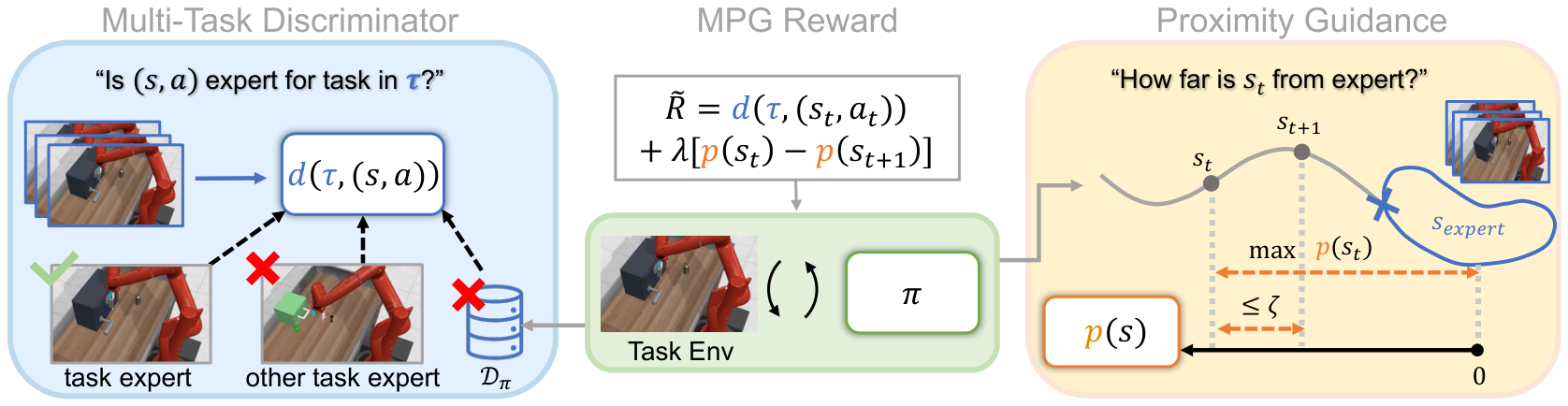
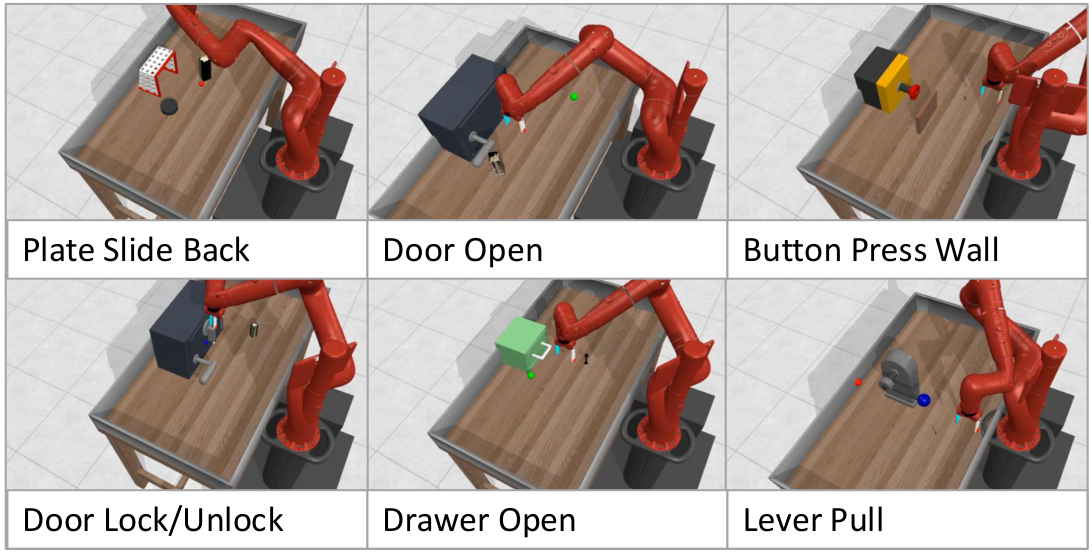
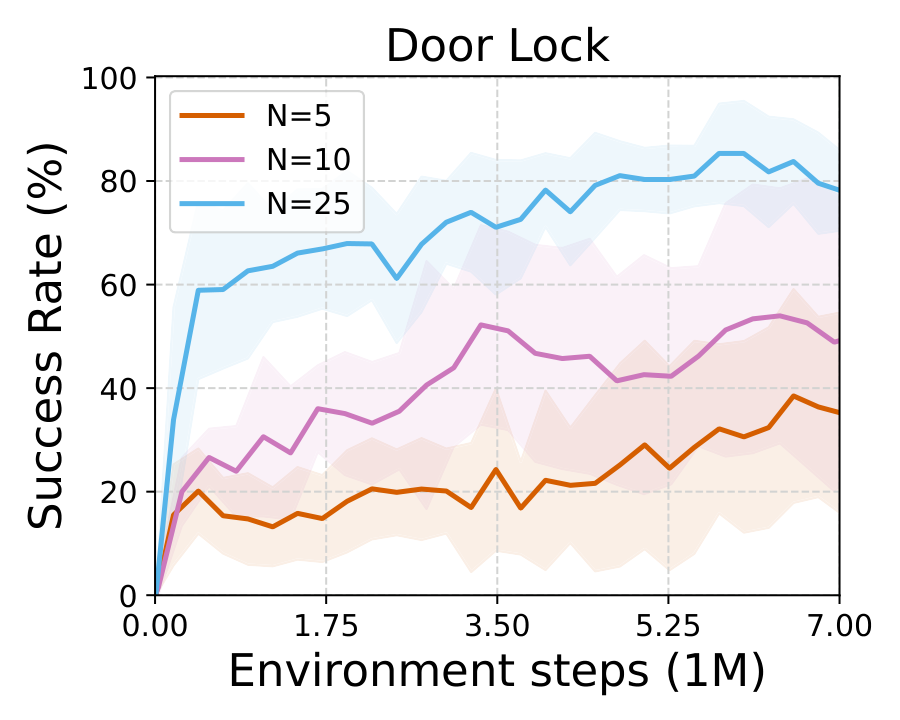
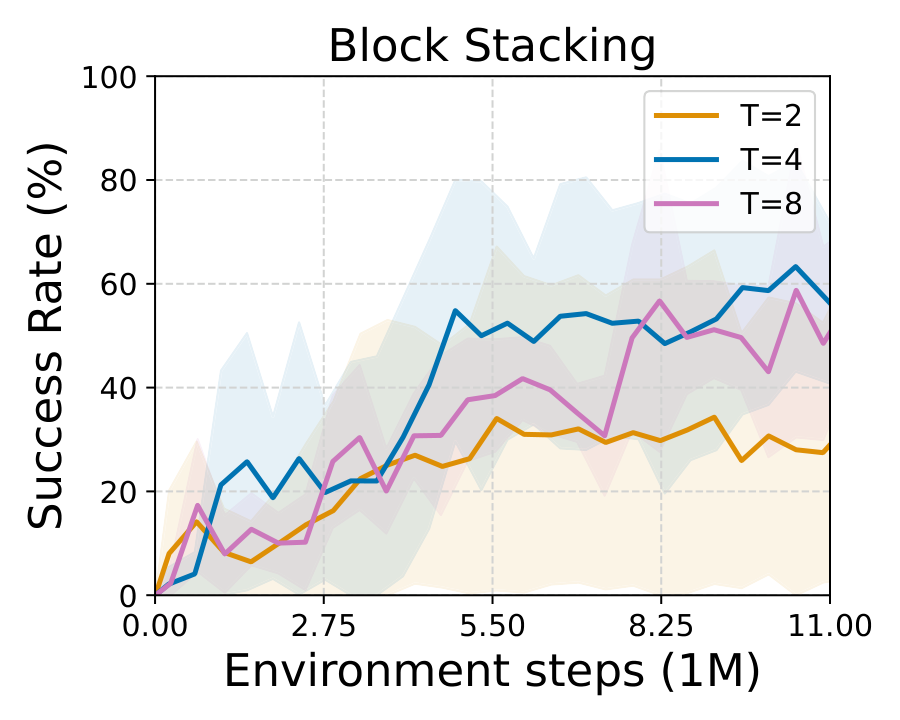
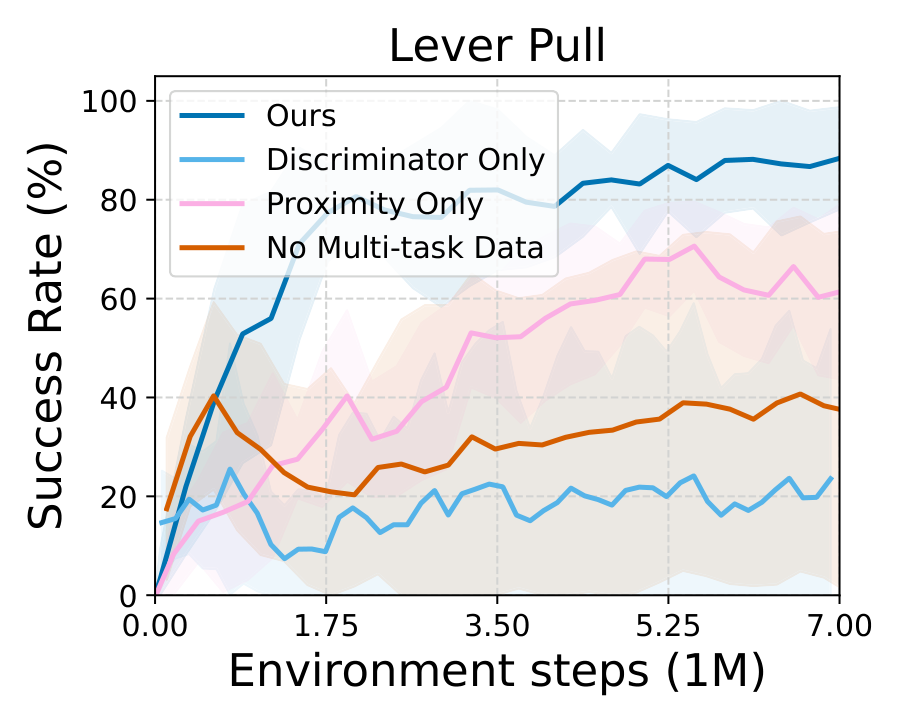
We introduce Multitask discriminator Proximity-Guided IRL (MPG), which learns two complementary reward components: (1) a generalizable discriminator that transfers shared structure across related tasks to identify expert behavior in a new task, and (2) a proximity function that measures how far a state deviates from expert behavior and provides corrective guidance during exploration. We demonstrate the effectiveness of our method on multiple challenging navigation and manipulation tasks under significant variations (e.g., object configurations, table layouts, and initial robot poses), achieving an average success rate of 81.2%, outperforming the strongest per-task baseline by an average of 24.7 percentage points.